Git is an Open source distributed revision control system with a focus on speed, efficiency and source code management. Git was originally developed and designed by Linus Torvalds for the development of the Linux kernel. With a tiny footprint and lightning fast performance, git is designed to fit any project, regardless of its size and nature. It outclasses many SCM tools that have features such as cheap local branching, convenient staging areas and multiple workflows.
“git” can mean anything, depending on your mood.
Linus Torvalds (git Readme)
- random three-letter combination that is pronounceable, and not actually used by any common UNIX command. The fact that it is a mispronunciation of “get” may or may not be relevant.
- stupid. contemptible and despicable. simple. Take your pick from the dictionary of slang.
- “global information tracker”: you’re in a good mood, and it actually works for you. Angels sing, and a light suddenly fills the room.
- “goddamn idiotic truckload of sh*t”: when it breaks
Version Control System (VCS)
Version control system is a software tool that helps developers work in tandem without over-writing each others changes and keeping a complete history of their work. If an error occurs, developers can turn the clock back and compare earlier versions of the code to help resolve the problem while minimizing disruption to all team members. VCS are also known as SCM (Source Code Management) tools or RCS (Revision Control System). Traditional revision control systems use a centralized model in which all the operations for revision control take place on a shared server (Central Version Control System). But the major drawback of CVCS is its single point of failure. Also in case of centralized system, the central server needs to be powerful enough to serve requests of the entire team. Although the latest trend is to use distributed version control system (DVCS), which creates redundancy by fully mirroring the system in local platform as well. This also gives a huge benefit in terms of speed as most of the operations can be performed locally, and synchronized periodically with centralized server.
Why Version Control System is needed?
In today’s world it is very common to have larger development teams. In most of the scenario they will be distributed geographically in different locations. Unlike old days when development used to happen in same room it was easy to communicate and co-ordinate. If thousands of developers are working together it may be very common to have two people working on same file. Other case might be in case of mission critical projects it will be not helpful if any code pushed in main base has security venerability or error. Version control system not only facilitates to overcome the fallback of larger teams, it also helps in keeping track of development.
What is Git?
Git is a modern distributed version control system released under the GNU General Public License version 2.0. In some sense it might not be wrong to tell git is a byproduct of Linux development. After few years of first Linux kernel release, there were a lot of people contributing to the code. It was no more one man job to further develop the kernel. It grew in size multi-fold. Linus needed a system to review the submitted code before adding to base, as well as it should be easy to contribute without conflict. Git was developed for supporting Linux kernel development, inspired by BitKeeper and Monotone. In 10 years of time it became one of the major player in VCS world.
In many ways you can just see git as a filesystem – it’s content-addressable, and it has a notion of versioning, but I really designed it coming at the problem from the viewpoint of a filesystem person (hey, kernels is what I do), and I actually have absolutely zero interest in creating a traditional SCM system.
Linus Torvalds
When we discuss about “git”, it is very important to note that it is plane and simple “g-i-t”. It is not same as GitHub, GitLab or Bitbucket etc. These are just hosted code vaults which supports git. One doesn’t require subscription of any of these services to use git. Even a central server is also not required to use git. It can be used as simple personalized difference tracker. It doesn’t require to be only development environment, it might be useful for non development environments to track changes done in certain files. Git provides a way to track the changes and roll-back to a previous state in case of need.
Git Terminologies
Before digging deep into git it might be a good idea to glance through the common terminologies used in git environment for easy understanding of further concepts, and utilize them efficiently.
Repository
The archive, where current and past data of the files are stored, mostly on a computer. In git there are two repository: local and remote. Local repository is the private workspace of developer.
Blob
The contents of a file are a blob (binary large object). Blobs do not have a proper name for the file, time stamps or other metadata. (Internally, the name of a blob is a hash of their content.)
Tree
A tree-object is a directory equivalent. This includes a list of names of files, each with some form bits and a reference to a blob or the contents of that file, symbolic link, or directory. It is a snapshot of source tree.
Staging Area
Git is going a different route from other vcs. It doesn’t track every single modified file. Each time a commit operation is requested, git only searches for the files present in the staging area. This is an intermediate area where you can format and evaluate commits before completing the commit.
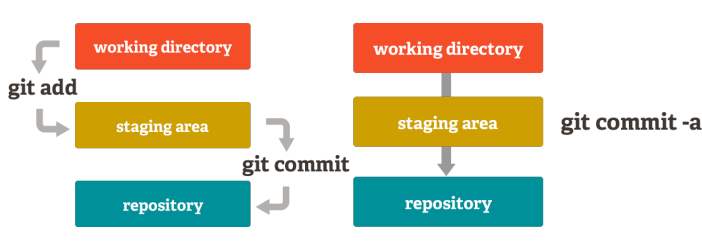
Commit
To commit is to write or merge the changes made in the working copy back to the repository. It holds the current repository status and named using SHA1 hash of content.
Head
HEAD is a pointer, that always points to the branch ‘s latest commit. If a commit is made, the current commit is updated to HEAD.
Branching and Merging
Branches are utilized to create another line of development. By default, Git has a master branch similar to trunk in Subversion. Git allows and encourages to have multiple local branches that can be entirely independent of each other. with help of branches development takes place without breaking the working version of code. Every branch is referenced by HEAD, which points to the latest commit in the branch. It takes only a few seconds to create, delete, and merge branches.
A merge is an operation that applies two sets of modifications to a file or collection of files. this provides a way for two of team members to work on different features in same file (on their local repositories) and later integrate them as one.
Tags
Tag assigns a descriptive name to the file, with a particular version. Tags are identical to branches, however the difference is that tags are unchangeable. It means, tag is a branch that no-one wants to change. e.g. product release.
Revision
Revision is the state at a instant in the entire tree inside repository . In Git, revisions are represented by commits, which are identified by SHA1 secure hash.
Checkout
Checking out involves making a local working copy from the archive. A user can decide, or get the latest version. When a file has been checked from a shared file server or another branch, other users can not edit it.
Diff
A diff or change represents a specific modification to a document under version control. It is very useful tool during debug process as current nonworking version can be compared to any previous working version.
Clone
Cloning means creating a repository which contains revisions from a different repository. With this local repository(cloned) users can do many operations. Network is only required when instances are being synchronized.
Push/Pull
Push operation copies changes from a local repository to a remote one while pull operation copies changes from remote repository and merges them to local repository. If remote repository is more updated then a pull operation might be required before push.
Why git?
- Free and open source
- Git supports a non-linear development by means of rapid branching and merging, and it includes specific tools for visualizing and navigating history.
- Unlike cheap copy (copies complete source code to new branch) git follows cheap branching which makes it light weight and fast. The core part of Git is written in C, which avoids runtime overheads associated with other high-level languages.
- Git only tracks the changes and communication from the server is done after compression of data. which has very low bandwidth requirement.
- Git gives each developer a local copy of the complete history of development, and changes are copied from one repository to another. The distributed nature of git gives most required feature of implicit backup.
- Git repositories can be published via HTTP, FTP, or a Git protocol over either a plain socket, or Secure Shell (ssh). With multiple emulation method (e.g. CVS server emulation) and plugins it is compatible with existing systems and protocols.
- In Git history, ID of a particular version depends upon the complete development history leading up to that commit. Once it is published, it is not possible to change the old versions without it being noticed. By such measures cryptographic authentication is built into core of git.
How git Works?
After investigating “what” and “why” it is always interesting to know “how?”. Git is focused on content. It can actually follow the move of content from one file to another file. Idea of staging area gives a pause to decide and control versioning system as needed. It is very efficient in network exchanges as both remote and local repository have complete copy so only small data is exchanged. On top of that compression makes sizes further smaller. In git everything is offline. commits, branches, history etc all happen at local repository, and occasionally only it is needed to communicate to central server for push or pull. In a simple pictorial manner it can be represented as three step process.
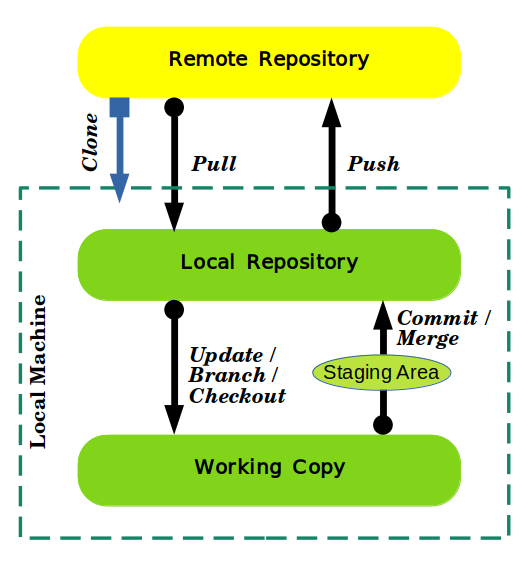
Being a distributed system git supports multiple workflow and hence suitable for different working styles. It is very flexible in terms of use cases. Here is an additional video from Linus Torvalds himself speaking about git.
In next article of the series we will look into getting started with git. Readers are encouraged to visit git website for more details. Let us know your query and questions in comment section.
- git – an intro to “The Stupid Content Tracker(TM)”